データレイクとは?メリットや注意点、構築に役立つサービスまで一挙にご紹介!
データ基盤・分析はじめに
データレイクとは何かをご存知でしょうか?構造化データや半構造化データを格納する集中型リポジトリ(データの保管場所)であり、ビッグデータの分析を行うシーンなどにおいて、非常に有効に使うことができます。本記事では、データレイクの概要やメリットに加えて、具体的な選び方や利用時の注意点まで、あらゆる観点から一挙にご説明します。自社でデータレイクの導入を検討されている方は、ぜひ最後までご覧ください。
開発から分析まで今必要な最適なAIサービスを選択「ユースケース別の生成AIサービス活用法」
目次
データレイクとは?
まずは、データレイクの概要についてご説明します。
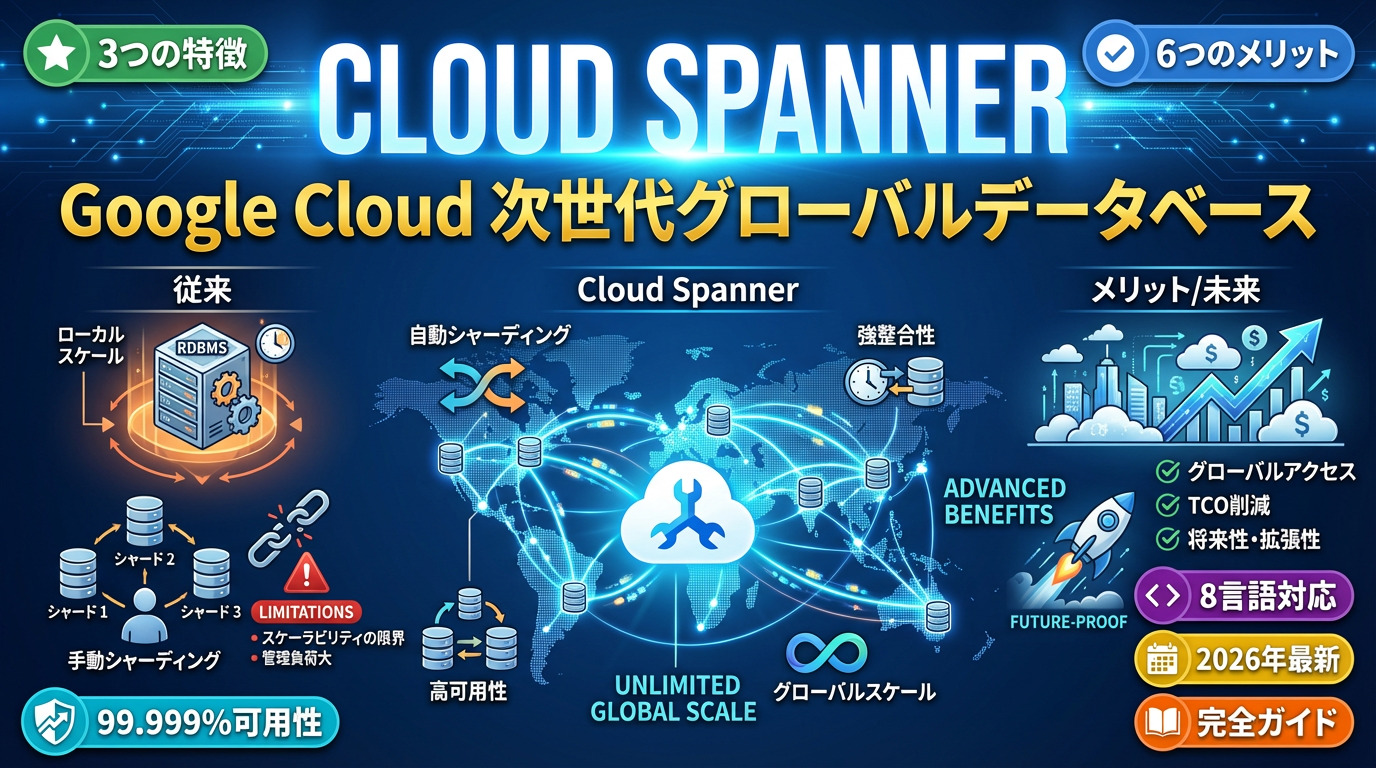
データレイクとは、構造化データや半構造化データを格納する集中型リポジトリ(データの保管場所)です。データレイクに保管されているデータは整理されていない状態で保存される点が大きな特徴であり、音声や動画など、様々な種類のデータを形式を変えずに格納できるため、ビッグデータの置き場所として活用されることも珍しくありません。
詳しくは後述しますが、データレイクは膨大なデータを一元管理できたり、データをそのままの状態で保管できたりするなど、様々なメリットを持っています。企業が保有するデータが肥大化・多様化している現代において、膨大なデータを分析・活用し、市場競争力の強化や自社のビジネス成長を実現するためには、データレイクが心強い武器の一つになると言えるでしょう。
データウェアハウス( DWH )とデータベースとの違い
データレイクと混同しやすい言葉として、データウェアハウス( DWH )やデータマートなどが挙げられますが、これらは明確に異なるものとして区別されています。本章では、データレイクと DWH ・データマートとの違いをそれぞれ解説します。
データレイクとデータウェアハウス( DWH )との違い
データウェアハウス( DWH )とは、膨大なデータを保管し、効率的に活用するためのリポジトリであり、日本語では「データの倉庫」と呼ばれています。大規模データを保管する点はデータレイクと共通していますが、 DWH の大きな特徴は保存されているデータが綺麗な状態に整理されていることです。
つまり、 DWH は元データを綺麗に整理した状態で格納するのに対して、データレイクは元データをそのままの形式で格納し、必要に応じてそれらを加工してからユーザーへ提供します。このように、データをどのような形式で保管するのかという観点において、両者は明確に異なるものだと言えるでしょう。
データレイクとデータマートとの違い
データマートという言葉は「 Data (データ)」と「 Mart (小売店)」という 2 つの英単語から形成されており、データウェアハウス( DWH )から特定の目的でデータを抽出・保管するための IT ツールを意味します。そのため、データマートは小規模な DWH だとイメージするのが理解しやすいでしょう。
一方、データレイクに格納されているデータは形式を変えずにそのまま保管されており、一般的には整理されていない状態で存在しています。つまり、抽出された元データは一旦データレイクへそのままの形式で格納され、それらを構造化したものが DWH へ、そして、 DWH から特定の目的に合致するものがデータマートへ移されることになります。
このように、データレイクと DWH 、データマートはそれぞれ異なるツールとして区別されているものの、お互いが密接に関係しています。以下の図では、データの収集・蓄積・活用のプロセスにおいて、前述した 3 つのツールがどのように使われるのかを示していますので、ぜひ内容を理解しておきましょう。
合わせて読みたい▽
データウェアハウス( DWH )とは?メリットや選定時のポイント、活用事例まで徹底解説!
データレイクのメリット
企業がデータレイクを導入することで、具体的にどのような恩恵を受けられるのでしょうか?本章では、データレイクの代表的なメリットを 3 つご紹介します。
大量のデータを一元的に管理できる
データレイクを利用する主なメリットの一つとして、大量のデータを一元的に管理できる点が挙げられます。従来のデータ管理システムでは、構造化されたデータのみを扱うことが一般的でしたが、データレイクでは構造化されていないデータや多様なデータ形式も取り扱うことができます。
これにより、企業は様々なデータソースからの情報を統合し、一元的に管理することが可能になります。例えば、顧客データやセンサーデータ、 Web のログ、ソーシャルメディアの投稿など、異なる形式のデータを一括して取り扱うことで、全体像を把握しやすくなるため、より包括的なデータ分析や意思決定に繋がります。
データをそのままの状態で保管できる
データをそのままの状態で保管できる点もデータレイクの大きなメリットです。従来のデータウェアハウス( DWH )では、データを事前に構造化してから保存する必要がありましたが、データレイクであれば、膨大かつ多様なデータを非構造化データのまま保存できます。
つまり、データを収集時点の形式でそのまま保存し、後から必要に応じて処理・分析を行うことが可能になります。これにより、データの保存や取り込みに関する制約が緩和され、データ活用における柔軟性の向上に直結します。
膨大なビッグデータを効率的に処理できる
データレイクの大きな特徴として、ビッグデータを効率的に処理できる点が挙げられます。データレイクは膨大かつ多様なデータをそのままの形式で格納できるため、音声や動画など、様々な種類のデータを一元保管するのに役立ちます。
このように、データレイクを利用すれば、自社の膨大かつ多様なビッグデータを 1 つの場所で管理し、必要に応じて活用することが可能になります。企業が保有するデータの肥大化・多様化が進み、ビッグデータ活用の重要性が高まっている現代において、ビッグデータ処理を効率化できる点は、データレイクの大きなメリットだと言えるでしょう。
データレイクの仕組み/アーキテクチャ
本章では、データレイクの仕組みやアーキテクチャをご紹介します。データレイクを理解するうえでは非常に重要なため、ぜひ内容を理解しておきましょう。
データソース
データレイクに保管されるデータは、形式を変えずにそのままの状態で格納されることが一般的です。
データの種類は多岐にわたり、
- 構造化データ(列や行の概念を持つ、綺麗な状態に整理されたデータ)
- 非構造化データ(音声や動画、画像など、構造化されていないデータ)
- 半構造化データ(一部のみ構造化されているデータ)
など、様々なものが存在しますが、データレイクはこれらのデータを生データのまま格納できるため、多種多様なデータを一元的に保管できる仕組みとなっています。
データの抽出・取り込み・保存
多くの企業は複数のシステムを並行的に利用しており、様々なデータが社内に点在していることが一般的です。しかし、これらのデータをデータレイクへ移動させれば、膨大かつ多様なデータを一箇所にまとめて保管することが可能になります。
なお、データソース(データが元々保管されている場所)からデータを抽出し、データレイクへ取り込みを行う際には、バッチ取り込み(バッチ処理で定期的にデータを取り込む方法)やリアルタイム取り込み(データをリアルタイムに取得しながら取り込む方法)など、様々な手法が存在します。
データカタログ
データレイクは生データをそのまま格納する場所であるため、必要なデータを必要なタイミングで簡単に検索するための工夫が重要です。そこで、効果を発揮するのがデータカタログという仕組みです。
データカタログとは、データに対してメタデータ(特定データを説明するための情報)を追加し、データへのアクセスや取得を容易にするためのプロセスです。このデータカタログを適切に活用することで、データレイクの利便性を大きく向上させることができ、より効率的なデータ管理を実現できます。
データのセキュリティ・ガバナンス
データレイクには自社の貴重な情報が格納されているため、データのセキュリティやガバナンスはとても重要なポイントだと言えます。これらを適切に行うことで、自社の機密データを保護しながら、データレイクを安全に運用することが可能になります。
例えば、アクセス制御をはじめとしたセキュリティ対策を施したり、データレイクを使用する際の運用ルールを定めたりするなど、より安全性を高めるための工夫を行うことが大切です。万が一、自社の機密情報が漏洩した場合は、取り返しの付かない事態に発展するリスクがあるため、セキュリティ観点でのチェックは怠らないように注意してください。
データレイクの選び方
データレイクを選定する際には、意識すべきポイントがいくつか存在します。本章では、データレイクの選び方を 5 つご紹介します。
必要容量
データレイクを選ぶ際には、必要容量が重要なポイントの一つになります。過剰な容量を選ぶとコストが無駄になる可能性がありますが、反対に容量が不足している場合、データの処理・分析に支障をきたすリスクが存在します。そのため、データの増加傾向や将来の拡張計画などを十分に考慮して、自社にとっての必要容量を事前に見積もることが大切です。
コスト
データレイクを導入する場合、
- ストレージ料金
- データの処理料金
- データの転送料金
など、様々なコストが発生します。
特にクラウドベースのデータレイクを選ぶ場合は、クラウドプロバイダーの価格体系や利用料金などを注意深く確認してください。また、コスト面だけでなく、将来的な拡張やアップグレードなどを見据えて、それらを実施する場合の追加コストも考慮しておくと安心です。
スケーラビリティ
データレイクのスケーラビリティは、将来的な拡張や変更に対応するための重要な指標になります。ビジネスは常に変化しており、データの増加や新たな要件追加などが発生する可能性があるため、柔軟にスケーリングできるデータレイクを選ぶことをおすすめします。また、スケーラビリティは性能や安定性にも影響を与えるため、複数のサービスを比較して、慎重に検討を進めてください。
セキュリティ
データレイクには、機密データを含む様々な情報が蓄積されるため、セキュリティはとても重要な要素になります。そのため、データの保護やプライバシーの確保、アクセスコントロールなど、各種セキュリティ機能が適切に実装されているかどうかを確認することが大切です。また、データの暗号化や監査ログの管理など、セキュリティ対策が十分であるかを確認するとともに、業界の規制・法令への適合可否をチェックすることも忘れてはいけません。
サポート
自社でデータレイクを使う場合、サポート体制も考慮すべき重要な要素だと言えます。問題が発生した際に、サービスプロバイダが迅速・丁寧にサポートしてくれるサービスであれば、ビジネスシーンでも安心して利用できます。また、自社の従業員の IT リテラシーが低い場合、導入後のトレーニングが充実しているデータレイクを選ぶことで、社員教育をスムーズに行うことが可能になります。
データレイクを利用する際の注意点
データレイクはとても便利なツールですが、利用する際には注意すべきポイントがいくつか存在します。本章では、データレイクを利用する際の注意点についてご説明します。
単なるデータ置き場にならないように注意する
データレイクを導入する際には、単なるデータの置き場としてだけではなく、データを有効活用するための戦略やプロセスを構築することが重要です。なぜなら、データをただ蓄積するだけでは、そのデータから価値を引き出すことが難しくなるからです。そのため、データレイクを導入する際には、データの収集や整理、分析、活用などを含めたデータの管理戦略を明確に定義し、それらを実行するためのプロセスを慎重に検討してください。
構築時に専門知識が求められるケースがある
データレイクを構築する際、状況によっては複雑なデータの処理・統合を行うための専門知識が求められます。特に、クラウドベースのデータレイクを導入する場合は、クラウドプラットフォームに関する知識やデータエンジニアリングのスキルが必要となるケースも存在し、せっかくデータレイクを導入しても使いこなせない可能性があります。
そのため、データレイクを導入する際には、専門的な知識を持った信頼できるベンダーと契約し、適切なサポートを受けることが大切です。また、データレイクの中には直感的な操作で使用できるものも存在するため、扱いやすいサービスを選択することも重要なポイントになります。
データレイク構築に役立つサービス
ここまで、データレイクについて詳しく解説してきましたが、データレイクを構築する際にはどのようなサービスを使えばよいのでしょうか?本章では、データレイク構築に役立つサービスを 3 つご紹介します。
Google Cloud Storage
Google Cloud Storage は Google 社のストレージサービスであり、 Google Cloud の一機能として提供されています。保存できるデータ量に制限がなく、格納したデータを必要に応じて何度でも取得できます。また、 Google Cloud Storage はマネージドサービス(サーバーの保守・運用の大部分をベンダーが担ってくれるサービス)であるため、自社の工数を削減しながらデータレイクを構築することが可能です。
Azure Data Lake Storage
Azure Data Lake Storage は Microsoft 社のストレージサービスであり、非常にスケーラブルで様々なワークロードに対応できる点が大きな特徴です。単一のストレージプラットフォームでデータサイロを解消できるほか、階層型ストレージとポリシー管理でコストを最適化できます。さらに、暗号化や高度な脅威対策などのセキュリティ機能でデータを保護できるため、安全な環境でデータレイクを構築することが可能です。
Amazon S3
Amazon S3 は Amazon 社のストレージサービスであり、スケーラビリティや可用性、セキュリティなど、あらゆる面において高いパフォーマンスを誇ります。業種や規模を問わず、様々な企業が Amazon S3 を利用しており、クラウドネイティブアプリケーションやモバイルアプリケーションなど、データレイクの構築以外にも多くのユースケースで活躍します。また、アクセスコントロールをきめ細かく設定できるため、自社の状況に合わせて柔軟にカスタマイズすることが可能です。
データレイクの活用事例
アパレルショップなどを展開する株式会社アダストリアでは、データ分析における次の 3 つの課題が顕在化していました。
- 複数のシステムが存在しており、必要データの収集に時間がかかる
- データ抽出後の抜け漏れや定義の確認に時間がかかる
- 本番相当のデータを扱うためのデータベース環境が存在しない
そこで同社は、上記の課題を解決するための手段として、ビッグデータを効率的に処理・分析するためのデータ基盤を構築することにしました。そして、データレイクを構築するための具体的なサービスとして、 Google Cloud の採用を決めたのです。
Google Cloud を選んだ理由としては、ビッグデータの活用を見据えた場合、 BigQuery を利用できるメリットが大きいと感じたためです。ただし、同社は BigQuery のみを利用しているわけではなく、 Google Cloud の様々なサービスを組み合わせて使いながら、高品質なデータレイクを構築しています。
例えば、データソースから取り込んだ膨大な生データは Google Cloud Storage へ集約し、構造化データと一緒に BigQuery へ保存しています。そして、 BigQuery でそれらのデータを加工しますが、加工のワークフローは Cloud Composer で管理しており、最終的なデータ分析作業にはデータポータルを活用しています。
このように、 Google Cloud のサービスをフル活用することで、高品質なデータレイクを効率的に構築し、自社の生産性向上に繋げた好事例となっています。なお、 Google Cloud の各種機能はマネージドサービスとして提供されているものが多く、自社の工数削減を実現できた点も特筆すべきポイントだと言えるでしょう。
合わせて読みたい▽
Google Cloud を活用したデータ基盤構築事例 6 選
まとめ
本記事では、データレイクの概要やメリットに加えて、具体的な選び方や利用時の注意点まで、あらゆる観点から一挙にご説明しました。企業がデータレイクを活用することで、大量データの一元管理や効率的なビッグデータ処理など、様々なメリットを享受できます。この記事を読み返して、重要なポイントを理解しておきましょう。
BigQueryを活用したデータ分析基盤の構築から、
ランニングコストの最適化まで専門家が支援
データ活用の次の一手を、専門家がご提案します
Google Cloud 環境の構築、ツールの導入・運用まで、一気通貫でサポート↓