BigQueryでデータ分析基盤を構築する完全ガイド|成功事例とコスト・権限管理のポイントを徹底解説
技術ブログはじめに
BigQueryを活用したデータ分析基盤構築の成功の鍵3点と実践ガイド、企業事例を紹介し、迅速かつ正確な意思決定を支える信頼性の高い基盤構築を解説します。。
開発から分析まで今必要な最適なAIサービスを選択「ユースケース別の生成AIサービス活用法」
データ分析基盤とは?なぜBigQueryが選ばれるのか
データ分析基盤の役割と重要性
データ分析基盤とは、企業内に散在する様々なデータを一元的に収集・統合し、分析しやすい形に整備するためのIT基盤です。これにより、データに基づいた意思決定を促進し、ビジネススピードの向上や新たなビジネスチャンスの創出に繋がります。
BigQueryがデータ分析基盤に最適な理由
BigQueryがデータ分析基盤として選ばれる主な理由は以下の通りです。
- スケーラビリティとパフォーマンス: ペタバイト級の大容量データを数秒で高速に処理できます。
- フルマネージド: サーバーの管理やインフラの運用が不要なため、データ分析に集中できます。
- SQL互換性: 標準SQLが使えるため、既存のスキルセットで容易に利用を開始できます。
- 他サービスとの連携: Looker StudioやVertex AIといったGoogle Cloudサービスとシームレスに連携できます。
- コスト効率: 処理したデータ量に応じた従量課金制のため、初期投資を抑えられます。
当社センティリオンシステム 大阪事業所では、データ初心者向けに Google Cloud が提供しているデータ分析サービスである BigQuery の
・アカウント設定
・プロジェクト作成
・基本的な SQL クエリ
・データの読み込み
・実践的な分析例
一つひとつ丁寧に解説します。お困りの方はお気軽にご相談ください。
センティリオンシステムの事業・導入事例は→こちら
BigQueryデータ分析基盤構築における3つの成功ポイント
ポイント1:データソースの洗い出しと設計
データ分析基盤を構築する最初のステップは、社内外にあるデータソースを特定し、どのようにBigQueryに取り込むか(ETL/ELT)を検討することです。データの連携方法や取り込み頻度、データ量に応じた設計が重要になります。
ポイント2:データモデルの最適化
BigQuery上でのデータモデルを最適化することは、パフォーマンスとコスト効率に直結します。
- パーティショニングとクラスタリング: データの絞り込みを効率的に行い、クエリの高速化とコスト削減を実現します。
- スター型スキーマ: データをファクトテーブルとディメンションテーブルに分けることで、分析の柔軟性を高めます。
ポイント3:可視化・活用ツールの選定と連携
分析したデータをビジネスに活用するためには、可視化ツールとの連携が欠かせません。Looker StudioやTableau、Power BIなどのBIツールと連携し、誰でも簡単にデータを活用できるダッシュボードを作成することで、データドリブンな文化を組織に浸透させることができます。
BigQueryデータ分析基盤構築の実践ガイド:基本的なステップ
ステップ1:Google Cloudプロジェクトの準備
まず、Google Cloudプロジェクトを作成し、BigQuery APIを有効化します。IAM(Identity and Access Management)を設定して、適切なユーザーに権限を付与します。
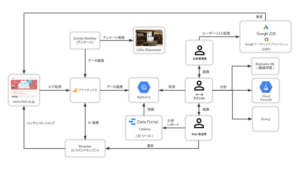
ステップ2:データ取り込み(ETL/ELTパイプライン構築)
様々なデータソースからBigQueryへのデータ取り込みは、Cloud Storage、Dataflow、Cloud Functions、Cloud ComposerなどのGoogle Cloudサービスを組み合わせて実現します。データの特性に応じて、バッチ処理とストリーミング処理を選択します。
ステップ3:BigQueryでのデータ加工と集計
BigQueryに取り込んだデータは、SQLを使ってクレンジング、変換、集計を行います。複雑なクエリはビューやマテリアライズドビューを活用することで、再利用性を高め、クエリのパフォーマンスを向上させることができます。
ステップ4:データ活用環境の構築
BigQueryとBIツールを連携し、データの活用環境を整えます。KPIを可視化したダッシュボードを作成し、定期的なレポーティングを自動化することで、データに基づいた意思決定を支援します。
コストを最適化する「一歩進んだ」テクニック
BigQueryは従量課金制ですが 、設計次第でさらにコストを抑えることが可能です 。
- 長期保存によるストレージ料金半額: 90日間更新されなかったテーブルは、自動的に「長期保存」とみなされ、保存料金が約50%割引されます。
- 定額料金(Capacity Pricing)の活用: クエリ量が多い大規模な環境では、計算リソースを予約する定額制プランを検討することで、月額費用の固定化とコスト削減が図れます。
- 「SELECT * 」を避ける: 必要なカラムのみを指定してクエリを実行することで、スキャンされるデータ量を最小限に抑え、課金額を直接的に削減できます 。
運用の要:BigQueryの階層構造と権限管理
BigQueryを安全かつ効率的に運用するためには、Google Cloud独自の階層構造を理解し、適切な権限(IAM)を設定することが不可欠です 。
- 3層構造によるデータ整理: 「プロジェクト > データセット > テーブル」の順に階層化されます。分析の目的や部署ごとに「データセット」を分けるのが一般的です。
- データセット単位のアクセス制御: 権限付与はテーブル単位ではなく、データセット単位で行うことで管理コストを抑えつつ、セキュリティを担保できます。
- 最小権限の原則: 全ユーザーに編集権限を与えるのではなく、閲覧のみの「BigQuery Viewer」やジョブ実行のみの「BigQuery Job User」など、役割に応じたIAM設定が推奨されます 。
構築時に注意すべき「よくある落とし穴」
成功のポイントを押さえる一方で、以下の失敗を避ける設計が重要です 。
- 後回しにできないスキーマ設計: BigQueryは柔軟ですが、パーティショニング(データ分割)などの設計を後から変更するのは手間がかかります 。初期段階でのクエリ頻度の予測が重要です 。
- データのサイロ化再発防止: 各部署が個別のプロジェクトを立てると、再びデータが分断されます 。全社共通のデータ分析基盤として、中央集権的なプロジェクト管理を検討してください 。
BigQueryデータ分析基盤構築の成功事例3選
1. 株式会社MonotaRO
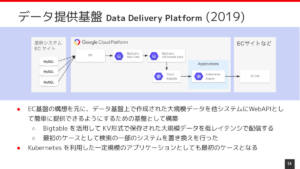
- 課題: 社内に散在する膨大なデータ(購買履歴、在庫情報など)の分析に時間がかかり、迅速な意思決定が困難でした。旧基盤のバッチ処理に多くの時間を要していました。
- 導入後の効果: BigQuery導入により、バッチ処理時間が大幅に短縮されました。また、非ITエンジニアでもLooker Studioを使って簡単にデータ分析や可視化ができるようになり、全社的にデータ活用のスピードが向上しました。
2. 三井ホーム株式会社
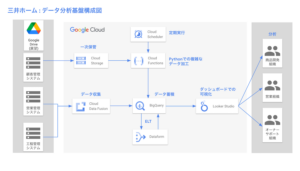
出典元:Google Cloud ブログ
- 課題: 各部署で個別にデータ収集・分析が行われており、データがサイロ化していました。全社的な共通指標での分析が困難でした。
- 導入後の効果: BigQueryを中核とした分析基盤を構築することで、データ収集プロセスが自動化され、全社で共通の指標に基づいたデータ分析が可能になりました。これにより、顧客満足度向上や業務改善に貢献しました。
3. 株式会社LIXIL
出典元:Google Cloud ブログ
- 課題: オンラインとオフラインの顧客データが分断されており、統合的なマーケティング分析が困難でした。顧客の行動全体を把握し、パーソナライズされた体験を提供することが課題でした。
- 導入後の効果: BigQueryでオンラインとオフラインのデータを統合することで、顧客一人ひとりの行動を詳細に分析できるようになりました。これにより、よりパーソナライズされたコンテンツ提供が可能になり、コンバージョンレートの向上を達成しました。
まとめ:Google Cloudでデータ駆動型経営を加速する
本記事では、BigQueryでデータ分析基盤を構築する重要性と、その成功ポイントを解説しました。スケーラビリティ、フルマネージド、他サービス連携の容易さがBigQueryの強みです。データソースの設計、データモデルの最適化、活用ツールの選定が成功の鍵となります。これらのポイントを押さえることで、データに基づいた迅速な意思決定とビジネス価値の創出が可能になります。
BigQueryを活用したデータ分析基盤の構築から、
ランニングコストの最適化まで専門家が支援
データ活用の次の一手を、専門家がご提案します
Google Cloud 環境の構築、ツールの導入・運用まで、一気通貫でサポート↓